自建开源治理工具
一、集成化趋势
整个研发工具的演进历程,就是集成化越来越高的历程。
- 个人工作面集成
最开始 ,我们只有一个一个的小工具,在Linux下还能通过管道把这些工具串联起来,或者自己写个Shell脚本,把任务串联起来。然后是IDE(Integrated development environment),将一个程序员用到的各种开发工具,集成到一起。
- 研发团队工具集成
随着研发工作,从单兵作战转变为团队协作,自然会需要研发团队需要的各种工具。例如团队存放代码,就需要SVN,或者Git。或者管理工作的某种任务跟踪工具(BugZilla、Jira或者其他工具)。
- DevOps集成
随着CI/CD的兴起,从最早的Make/CMake,演进到CruiseControl,Hudson/Jenkins这样的专业的CI工具。再加上从虚拟机到容器化的发展,持续发布、持续部署,流水线也不断出现。 到了2009的第一次DevOpsDays大会召开,开发、测试、发布、部署被集成到为一个整体。
- 复用组件与集成
除了工具层面的演进,另一种提高效率的努力,是尽可能的复用已有的工作成果。无论是公司内部的自研代码,还是来自于开源&第三方的组件与代码,都被集成到现有的产品之中。 现代高阶语言的标配“包管理工具”,也大大的推动了这一趋势。
- 企业级集成
在走过研发团队集成与研发&运维团队集成的阶段之后,我们开始考虑公司范围的工具集成、流程规范与资源统筹。 比如:公司级的代码托管平台,公司级的构建与部署平台,公司级的开源及第三方资产管理平台。这样做的目的主要有两个:
- 应对系统性风险。比如:需要统一的开源漏洞与法务合规管理
- 挖掘资产价值。比如:盘点现在使用的各种复用资产,减少多版本无序使用,减少生命周期维护压力
在这样的演进过程中,我们越来越清楚的注意到:研发工具不仅仅是工具,同时还是数据/资产管理,流程/权限管控。
二、开放性趋势
最开始是UNIX秉承的Everything is a file的设计哲学,就使得各种简单好用的小工具可以方便自由的组合使用。从早期的单一工具的插件化,到整个研发工具形成一个开放性平台,这个趋势越来越明显。
- 插件化
首先是各种编辑器的插件,例如VIM、Emacs的各种插件。在IDE出现之后,各种插件更是层出不穷。比较著名的插件体系包括:Eclipse/NetBeans这样的IDE上的插件,FireFox/Chrome浏览器上的各种插件,Redmine这样的管理工具加代码托管平台的各种插件,Jenkins作为一个CI/CD平台的插件生态也非常繁荣。
- API、WebHook与开放平台
即使不提供插件,很多开发工具都开始提供规范的API,供周边工具调用。这方面GitHub是一个非常好的榜样,提供了第一流的API、WebHook,后来还开设了应用市场、Actions等等扩展能力。
- Everything as Code
从虚拟机到容器的过程中,基础设施可编程也变得越来越重要,随着Chef、Puppet这样的工具开始流行,Infrastructure as code就不再是一句口号了。
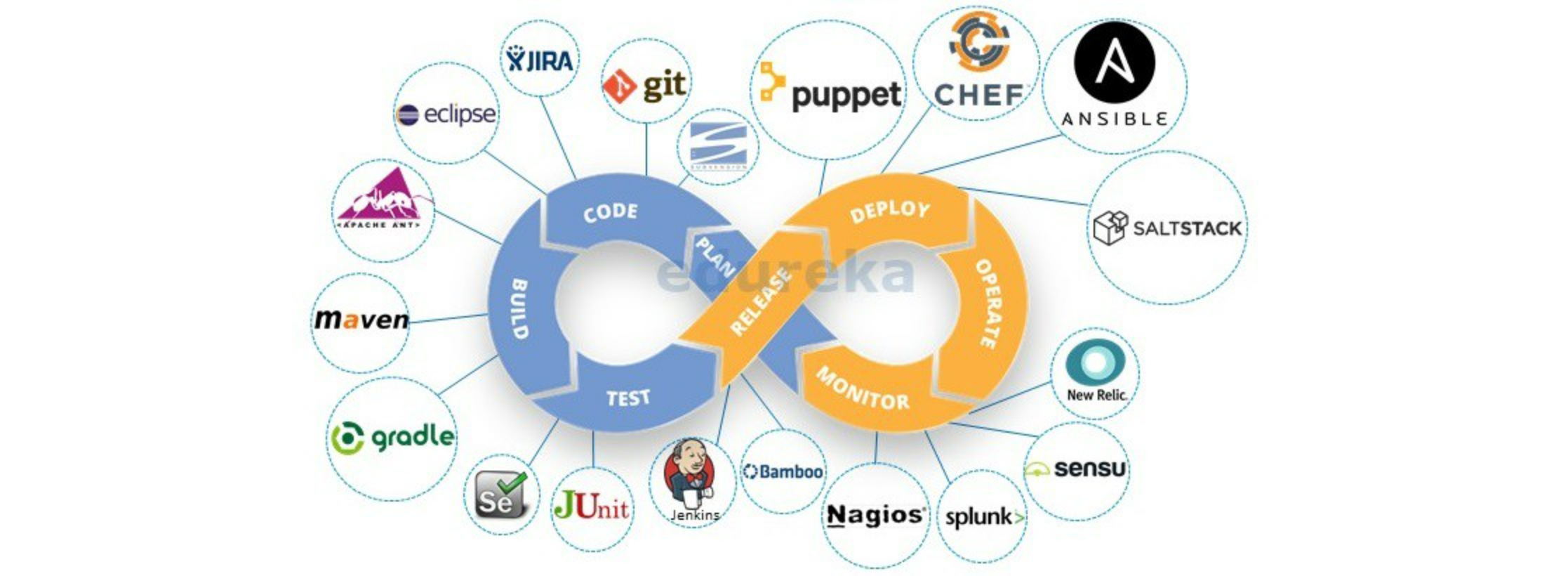
随着越来越多的工具组成一个DevOps整体,而其中的每一份子都具备一定的开放性与可编程能力,Everything as Code就被提上议事日程了。
- 开发与执行环境联网
除了研发工具的演进趋势,我们整个开发的环境也在变得越来越开放。以前,我们可以在一台完全不联网的计算机上,安安心心的写自己的代码。但是现在我们的开发环境必须是联网的。我们开发完成的系统,也会部署到一个开放的环境中,无法避免外部的访问(或侵扰)。
- 软件架构的开放性
在有了各种编程语言自带的包管理工具,有了繁荣丰富的开源组件生态以后,我们的开发工作量已经变得:Finding > Coding 了。 这也使得我们的架构,更多的需要考虑“拼接”的问题,而不仅仅是我们自己从头设计并实现一个架构。
三、数字化趋势
在我看来,研发工具体系在越来越庞大、复杂之后,也需要思考数字化转型的问题。在讨论研发工具的数字化之前,我们先来讨论一下数字化本身的趋势。虽然,我们一直会觉得,相比起传统行业,IT工具本身,当然已经是数字化的了。
- 散落在各种地方的数据
数字化转型首先需要解决的难题,就是找到数据在哪里?在收集数据的过程中,我们就会发现数据是散落在各个地方的,格式不同,存取方式不同,可能还有一些都没有数字化(这方面IT工具会好一些)。 同样的,在研发工具集成化的过程中,我们也会发现:数据是散落在各个研发工具之中的。他们之前并没有考虑过,会如何被集成。有文件型的数据,有纯文本的数据,有存储在关系型数据库里的数据,还有一些自定义的格式,例如.git文件夹里的数据。如果在我们的研发工具中,还用到了不开源(不开放)的工具,那就更加麻烦。
- 结构化、标准化与元数据管理
一旦考虑集中存放,我们得思考数据之间的关系,以及如何将这些关系通过某种方式存储下来,并且在后续可以实现多种利用的机会。这样,将各种异构的数据进行结构化,标准化就会成为首先需要解决的难题。 同样的,在研发工具集成的过程中,我们也需要考虑研发相关数据的集中存储,在不破坏原有工具自然架构的前提下,如何设计数据湖、API和ESB,如何设计全局一致的一套元数据规范,并进行有效管理,也是在研发工具集成过程中的首要难题。
- 数据作为一种资产
阿里巴巴对数字化转型有一个经典的定义:“一切业务数据化,一切数据业务化。”按照我的解读,前一句话,就是将所有能够数字化的内容,都进行数字化处理。而后一句话,则是将所有已经数字化的内容,视做一种资产,考虑如何保护资产、如何使资产不断增值,发挥其更大的价值。 在研发工具的领域,同样可以发现各种各样的研发数据,包括资产数据、行为数据、日志数据等等,这些数据如何资产化?如何被更好的利用,是一个始终没有被很好的解决的问题。
- 支撑智能化